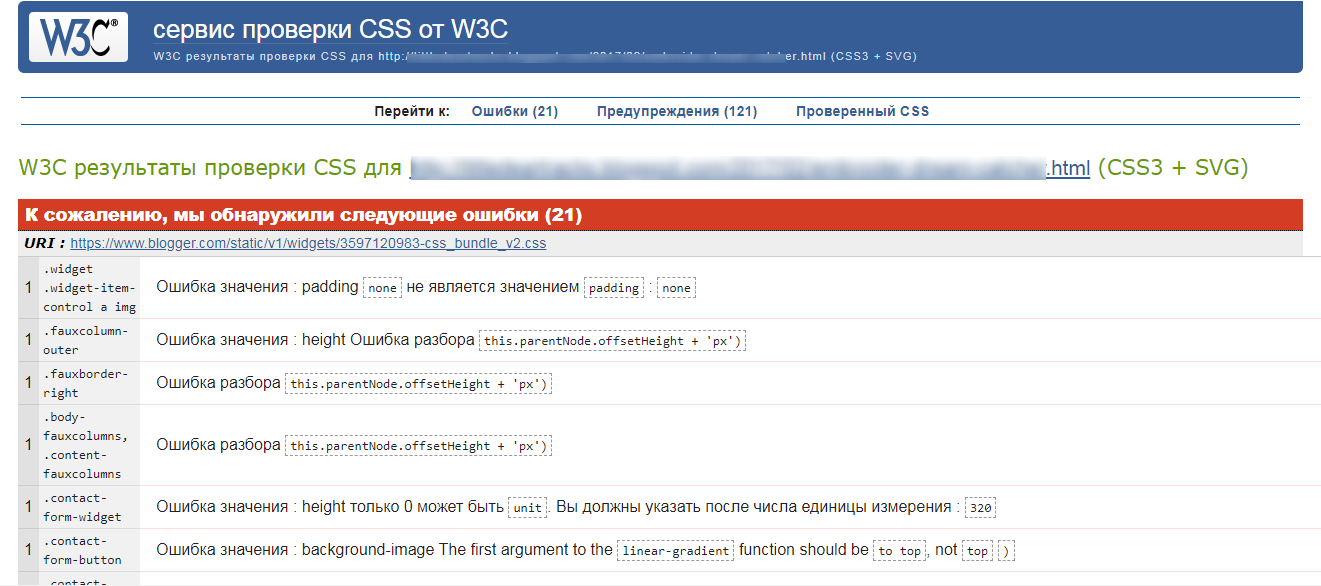
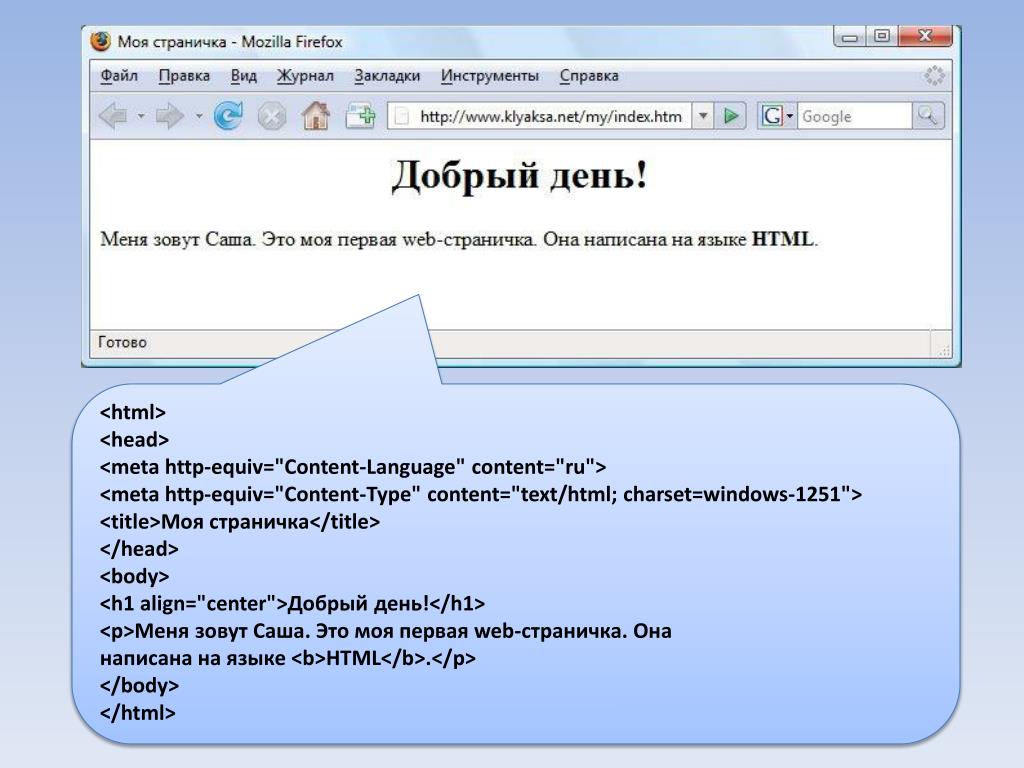
Кодировки UTF-8 и Windows 1251 — просто о сложном
Здравствуйте, уважаемые читатели моего блога. Сегодня мы поговорим с вами про кодировку. Если вы читали мою статью о том, как посмотреть код страницы в браузере, то знаете, что любой документ в интернете хранится не в том виде, в каком мы привыкли его видеть. Он записан при помощи непонятных человеку символов и знаков. С текстом все точно также.
Существует несколько кодировок, а потому, иногда увидев непонятные символы при открытии книги в мобильном приложении или запилив статью на сайт, вы, поменяв кое-какие значения в настройках, увидите привычный глазу алфавит.
Кодировка windows-1251 – что это такое, какое значение она имеет при создании сайта, какие символы будут доступны и является ли она лучшим решением на сегодняшний день? Обо всем этом в сегодняшней статье. Как всегда, простым языком, максимально понятно и с минимальным количеством терминов.
Настройте буферы командной строки с историческими записями
Буфер служит исторической записью команд, которые вы выполнили, и вы можете перемещаться по командам, которые вы ранее ввели в командной строке, с помощью клавиш со стрелками вверх и вниз. Вы можете изменить настройки приложения для буферов в разделе «История команд» на вкладке «Параметры».
Настройте, сколько команд сохраняется в буфере команд, установив размер буфера. Хотя по умолчанию установлено 50 команд, вы можете установить его равным 999, но имейте в виду, что это занимает ОЗУ. Проверка опции «Discard Old Duplicates» в нижней части раздела позволяет Windows 10 удалять дубликаты записей команд из буфера.
Вторая опция, «Количество буферов», определяет максимальное количество одновременных экземпляров, чтобы иметь свои собственные буферы команд. Значение по умолчанию — 4, поэтому вы можете открыть до четырех экземпляров командной строки, каждый со своим отдельным буфером. После этого ограничения ваши буферы перерабатываются для других процессов.
Где искать в Windows
Таблицы кодов символов по умолчанию вмонтированы в операционную систему “Виндовс”. С их помощью юзер сможет печатать буквы и специальные знаки в любом текстовом редакторе или документе.
Для того, чтобы найти таблицу символов в “Виндовс”, нужно:
- Открыть пункт меню “Пуск”.
- Развернуть раздел “Все программы”.
- Выбрать папку “Стандартные”
- Кликнуть по надписи “Служебные”.
- Заглянуть в приложение “Таблица символов”.
Дело сделано. Теперь можно изучить все возможные знаки, которые только могут восприниматься операционной системой. Если дважды кликнуть по миниатюре того или иного символа, а затем щелкнуть по кнопке “Скопировать”, соответствующий знак будет перенесен в буфер обмена. Из него можно выгрузить данные в текстовый документ.
Важно: в нижней части окна справа можно увидеть сочетание клавиш для быстрой печати выбранного элемента, а слева – “Юникод” для набора в тексте
Chcp 1251 что это: кодировка виндовс
На днях пришлось решать небольшую проблему с плохой восприимчивостью комплекта Denwer к кодировки UTF-8. Проблема, честно говоря, оказалась пустяковая, и была решена минут за 15, 10 из которых заняло использование Гугла. В этом время, исследуя различные форумы, я заметил, что для многие не могут разобраться с этой проблемой достаточно долго. Кроме того, понял, что многих интересует зачем вообще использовать UTF-8, если есть прекрасная такая “русская” кодировка Windows-1251. Вот и решил написать пару постов на эту тему. Начну я с общего описания данных кодировок, а продолжу, непосредственно, описанием решения проблемы использования UTF-8 на пакете Denwer.
Не так давно, в связи со сложившимися обстоятельствами, решил отказаться от кодировки Windows-1251, с которой работал очень давно, и целиком и полностью перейти на UTF-8. Все причины перехода раскрывать не буду, но основные из них:
- большинство современных веб-платформ по-умолчанию работают именно на ней;
- её очень удобно использовать для создания мультиязычных проектов;
- набор используемых в кодировки символов около 100000;
- кодировка универсальная, т.е. русские символы и в Никарагуа остаются русскими.
Далее постараюсь написать несколько слов об основных отличиях кодировок Windows-1251 и UTF-8, а так же, в качестве бонуса, примеры объявления кодировки в HTML, PHP и для работы с базами данных MySQL.
Немного теории
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
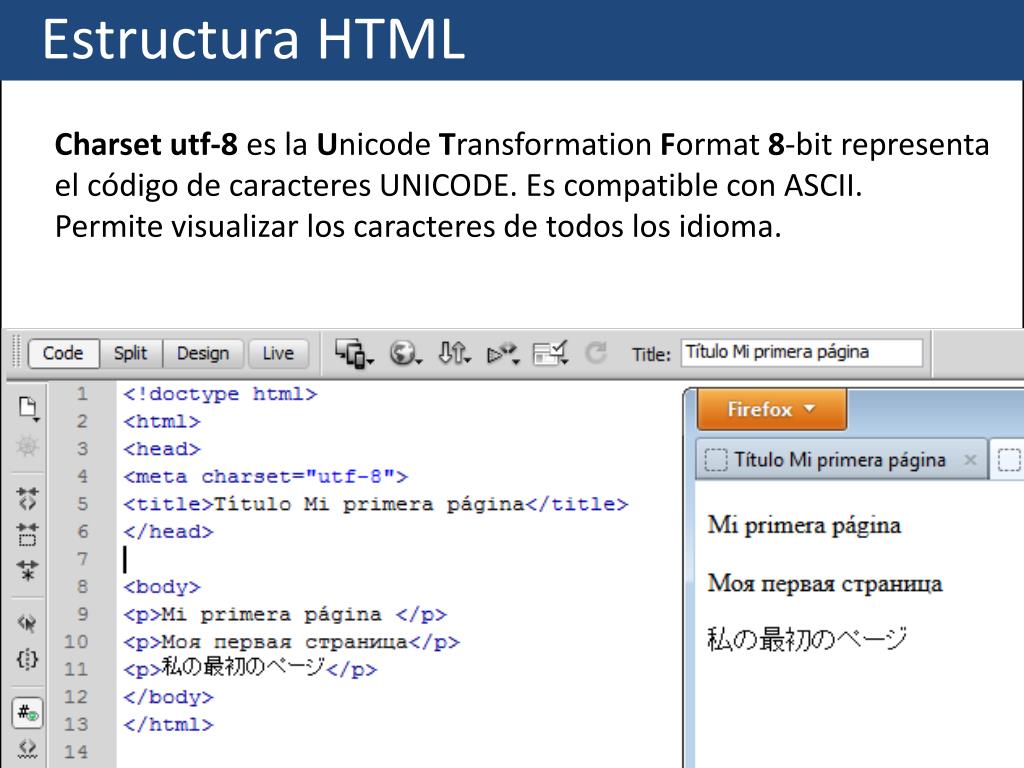
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Основные отличия кодировок
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251.
Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
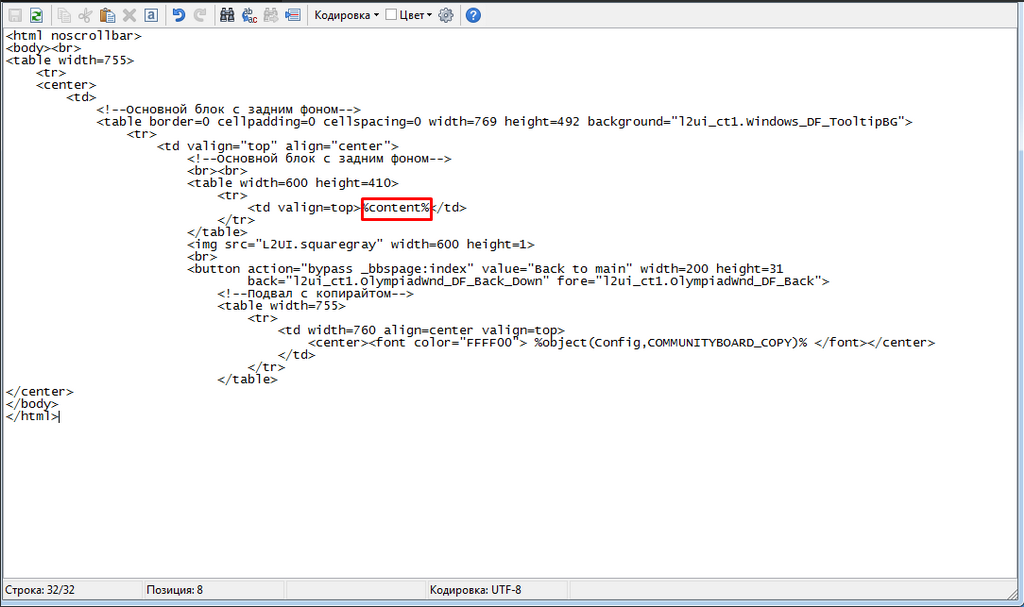
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Плюсы UTF-8:
- UTF-8 позволяет работать одновременно с несколькими языками, т.е. выдавать тексты, в которых используются символы разных алфавитов и даже иероглифы. С использованием кодировки 1251 это невозможно;
- использование UTF-8 позволяет отказаться от кодовых таблиц, трансляций символов и всех прочих извращений, что были ранее с однобайтовыми кодировками;
- Нет кучи кодировок для одного и того же языка, как это было ранее для русского: cp1251, cp866, koi8r, iso8859-5.
Минусы UTF-8…
А есть ли они у этой кодировки вообще? Я знаю только разных мифах и легендах на эту тему, вот некоторые из них: “У UTF-8 есть проблемы со старыми браузерами” – маловероятно… Во всяком случае, если под старыми не подразумевают Lynx и Mosaic _); “С UTF-8 возникают проблемы на сервере” – ну да, если сервер по-умолчанию пытается определить другую кодировку. Но это не минус кодировки, уж точно…
Кодировка windows 1251 в html
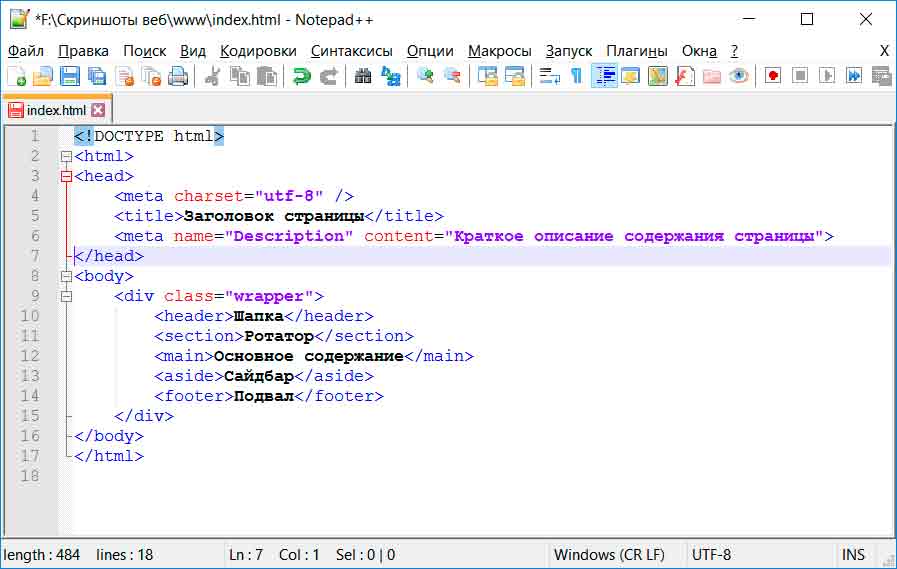
Нередко у web-разработчиков и блогеров, обладающих различной квалификацией возникает проблема с кодировкой страниц: вместо подготовленного текста появляются неизвестные, нечитаемые символы. Чтобы разобраться с данной проблемой, необходимо понимать суть термина «кодировка страницы».
Текст в памяти компьютера хранится в виде определенного количества байт, а не в том виде, в котором он отображается в текстовом редакторе. Каждый байт является кодом, который соответствует одному символу. Для того чтобы текст на странице отображался как следует, нужно сообщить браузеру, какую таблицу кодов для расшифровки и отображения он должен использовать.
Таблица кодировок не является универсальной, то есть, для расшифровки текста необходимо использовать ту, которая соответствует кодировке символов:

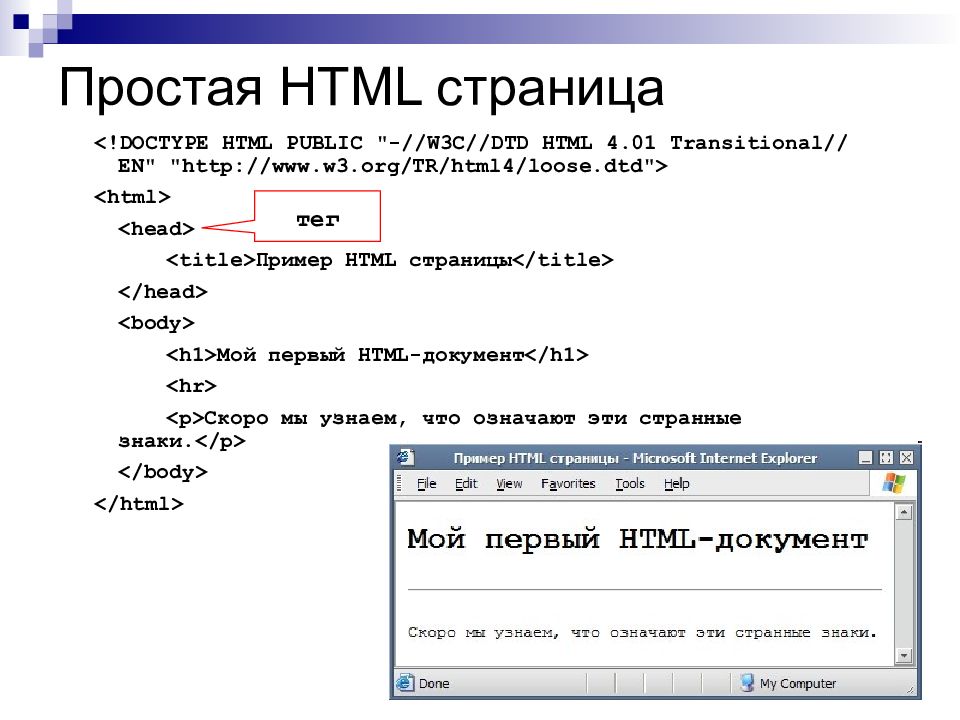
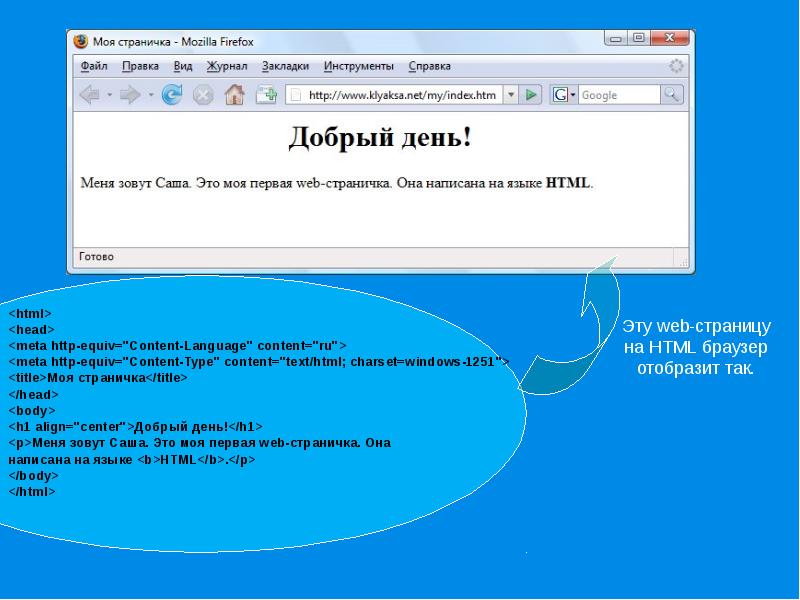
Для того чтобы html-документ корректно отобразился в браузере, необходимо указать используемую кодировку. Делается это следующим образом:
— между тегом <head> и закрывающим его </head> нужно прописать <meta http-equiv=»Content-Type» content=»text/html; charset=utf-8″> — исходя из этой строки, браузер будет использовать символы русского алфавита для отображения текста на странице.
Кодировка windows 1251 в PHP
Ни для кого не является тайной, что генерация страниц проходит путем выборки и использования какой-то части информации, которая хранится в базе данных. При написании сайта на PHP, чаще всего это mysql:

Нередко при смене хостинга возникает проблема: различные кодировки информации в базе данных и в шаблонах страниц. Из-за этого одна сгенерированная страница может одновременно содержать несколько кодировок. Если информация на сайте представлена в кодировке виндовс 1251, то и чтение из базы данных должно осуществляться с помощью таблицы, в которой представлена win 1251 кодировка.
Для согласования расшифровки необходимо выполнить функцию mysql_query(«SET NAMES cp1251») – это означает, что преобразование из машинного кода будет осуществляться согласно таблице cp1251.
Кодировка windows 1251 в htaccess
При создании сайта, предварительно настроив кодировки в шаблонах и базах данных, все равно может всплыть проблема некорректного отображения информации в браузере.
Для того чтобы для веб-ресурса была задана кодировка виндовс-1251, необходимо найти (или создать) файл .htaccess. Это файл, который хранит в себе дополнительные настройки и описания конфигураций web-сервера.
В нем для установки кодировки следует прописать следующие строки:
- DefaultLanguage ru;
- AddDefaultCharset windows-1251;
- php_value default_charset «cp1251».
Таким образом, для корректного отображения текста должны совпадать его кодировка и таблица кодов, с помощью которой браузер будет расшифровывать символы. Для текстов, написанных на славянских языках, необходима win 1251 кодировка
Важно помнить, что элементы страниц и баз данных должны быть описаны с помощью одной таблицы кодов
Неправильная кодировка HTML страниц
Создадим тестовый файлик:
sudo gedit /var/www/html/encoding.html
Скопируем в него следующий HTML код, в котором отсутствует указание кодировки и посмотрим, какие проблемы могут с ним возникнуть и как их решить:
<html>
<head>
<title>Проверка кодировки</title>
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Откроем этот файл в браузере http://localhost/encoding.html
Как можно видеть, кодировка браузером определена неправильно:
Имеется несколько способов исправить эту ситуацию. Начнём с самого простого – явно указать кодировку для веб-страницы. Это делается метатегом, который должен быть расположен внутри тэга head:
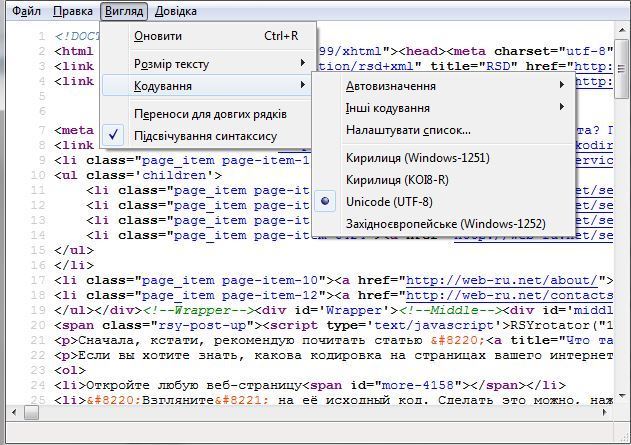




<meta http-equiv="content-type" content="text/html; charset=utf-8" />
Добавим эту строку к нашему тестовому файлику, чтобы получилось так:
<html>
<head>
<title>Проверка кодировки</title>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Как мы можем убедиться на следующем скриншоте, проблема решена:
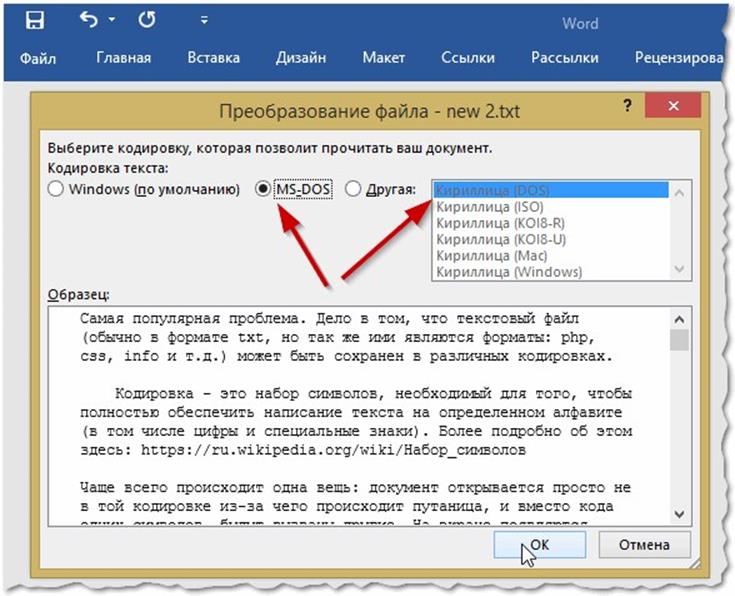
Если кодировка вашего файла отличается от UTF-8, то вместо неё поставьте windows-1251 или ту, которая соответствует кодировке веб-страницы. Чтобы научиться определять кодировку файлов, посмотрите эту инструкцию.
Это был самый простой способ исправления проблемы с кодировкой – без изменения настроек сервера.
Вернём наш тестовый файл в исходное состояние и продолжим изучение способов указания кодировки.
Если файлы .htaccess включены настройками Apache, то эти файлы можно использовать чтобы указывать кодировку отправляемых веб-сервером страниц. Чтобы включить поддержку файлов .htaccess в конфигурационном файле Apache ( /etc/apache2/apache2.conf ) найдите группу строк
<Directory /var/www/> Options Indexes FollowSymLinks AllowOverride None Require all granted </Directory>
И в ней замените
AllowOverride None
на
AllowOverride All
После этого сервер нужно перезапустить.
sudo systemctl restart apache2.service
Файл .htaccess должен быть размещён в той же директории, что и сайт. Мой сайт размещён в корневой директории веб-сервера. Если у вас также, то теперь в папке /var/www/html/ создайте файл .htaccess и добавьте в него директиву AddDefaultCharset после которой укажите желаемую кодировку. Примеры
AddDefaultCharset UTF-8
ИЛИ
AddDefaultCharset windows-1251
Можно указать кодировку, которая будет применена только к файлам определённого формата:
AddCharset utf-8 .atom .css .js .json .rss .vtt .xml
Набор файлов может быть любым, например:
AddCharset utf-8 .html .css .php .txt .js
Следующий вариант является альтернативным и также позволяет устанавливать кодировку для файлов определённого типа, для него нужно, чтобы был включён mod_headers:
<Files ~ "\.html?$">
Header set Content-Type "text/html; charset=utf-8"
</Files>
Ещё один вариант, который также можно использовать в файле .htaccess для установки кодировки UTF-8:
IndexOptions +Charset=utf-8
Если сайт на PHP, то дополнительно может понадобиться продублировать кодировку с php_value default_charset:
AddDefaultCharset windows-1251 php_value default_charset "cp1251"
Можно вместо создания файла .htaccess установить кодировку в конфигурационном файле веб-сервера. Для Apache CentOS/Fedora это файл httpd.conf, а на Debian/Ubuntu это файл apache2.conf. Добавьте следующую строку для установки кодировки и перезапустите веб-сервер, чтобы изменения вступили в силу:
AddDefaultCharset UTF-8
Что такое кодировка текста? Юникод и кодировки Utf-8, ANSI, Windows-1251

Charsets
Часто в веб-программировании и вёрстке html-страниц приходится думать о кодировке редактируемого файла — ведь если кодировка выбрана неверная, то есть вероятность, что браузер не сможет автоматически её определить и в результате пользователь увидит т.н. «кракозябры».
Возможно, вы сами видели на некоторых сайтах вместо нормального текста непонятные символы и знаки вопроса. Всё это возникает тогда, когда кодировка html-страницы и кодировка самого файла этой страницы не совпадают.
Собственно, основные параметры, которыми различаются кодировки — это количество байтов и набор спец.символов, в которые преобразуется каждый символ исходного текста.
Краткая история кодировок:
Одной из первых для передачи цифровой информации стало появление кодировки ASCII — American Standard Code for Information Interchange — Американская стандартная кодировочная таблица, принятая Американским национальным институтом стандартов — American National Standards Institute (ANSI).
В этих аббревиатурах можно запутатьсяДля практики же важно понимать, что исходная кодировка создаваемых текстовых файлов может не поддерживать все символы некоторых алфавитов (к примеру, иероглифы), потому идёт тенденция к переходу к т.н. стандарту Юникод (Unicode), который поддерживает универсальные кодировки — Utf-8, Utf-16, Utf-32 и др
Самая популярная из кодировок Юникода — кодировка Utf-8. Обычно в ней сейчас верстаются страницы сайтов и пишутся разные скрипты.
А также некоторые веб-технологии (в частности, AJAX) способны нормально обрабатывать только символы utf-8.
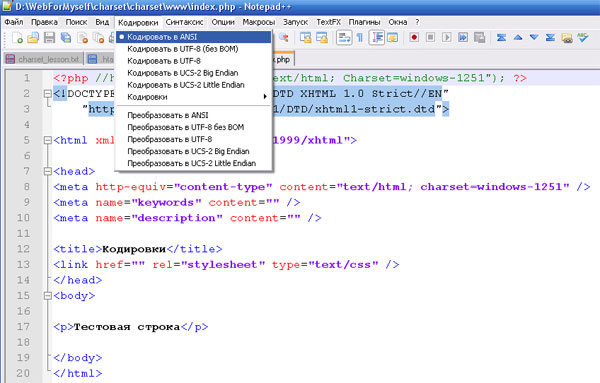
Установка кодировок текстового файла при создании его обычным блокнотом. Кликабельно
В Рунете же ещё можно встретить сайты, написанные с расчётом на кодировку Windows-1251 (или cp-1251). Это специальная кодировка, предназначенная специально для кириллицы.
(1
Usage
Basic API
var iconv = require("iconv-lite");
// Convert from an encoded buffer to a js string.
str = iconv.decode(Buffer.from(0x68, 0x65, 0x6c, 0x6c, 0x6f), "win1251");
// Convert from a js string to an encoded buffer.
buf = iconv.encode("Sample input string", "win1251");
// Check if encoding is supported
iconv.encodingExists("us-ascii");
Streaming API
// Decode stream (from binary data stream to js strings)
http.createServer(function (req, res) {
var converterStream = iconv.decodeStream("win1251");
req.pipe(converterStream);
converterStream.on("data", function (str) {
console.log(str); // Do something with decoded strings, chunk-by-chunk.
});
});
// Convert encoding streaming example
fs.createReadStream("file-in-win1251.txt")
.pipe(iconv.decodeStream("win1251"))
.pipe(iconv.encodeStream("ucs2"))
.pipe(fs.createWriteStream("file-in-ucs2.txt"));
// Sugar: all encode/decode streams have .collect(cb) method to accumulate data.
http.createServer(function (req, res) {
req.pipe(iconv.decodeStream("win1251")).collect(function (err, body) {
assert(typeof body == "string");
console.log(body); // full request body string
});
});
Изменение кодовых страниц для исправления иероглифов Виндовс 10
Кодовые страницы являются таблицами, в которых определенные символы сопоставляются определенным байтам, а отображение кириллицы в качестве кракозябров в Windows 10 связано с установкой по умолчанию не той кодовой страницы. Это исправляется различными способами, которые будут полезными, когда нужно в параметрах не изменять системный язык.
Редактор реестра
К первому способу относится использование редактора реестра. Это будет наиболее щадящим методом для системы, тем не менее, лучше создать точку восстановления перед началом работы.
- Нажимаем клавиши «Win+R», затем следует ввести regedit и подтвердить Enter. Будет открыт реестровый редактор.
- Переходим к меню HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsCodePage, а в правой части нужно пролистать значения до конца данного раздела.
Теперь кликаем дважды по параметру ACP, где устанавливаем значение 1251 (для кириллицы это кодовая страницы), нажимаем «Ок» и закрываем реестровый редактор.
Перезагружаем компьютер (нужна именно перезагрузка, а не простое завершение работы). Для Виндовс 10 это имеет значение.
Зачастую это обеспечивает исправление проблемы с неправильным отображением букв на русском языке. Вариация способа с использованием реестрового редактора (менее предпочтительная) – узнать текущее значение ACP параметра (часто – 1252 для изначально установленной англоязычной системы). Потом в данном разделе нужно отыскать значение параметра 1252 и заменить его с c_1252.nls на такое c_1251.nls.
Изменение на c_1251.nls файла кодовой страницы
Данный способ подойдет для тех пользователей, кто считает вариант с правкой реестра достаточно опасным или сложным. Здесь необходимо осуществить подмену файла кодовой страниц по пути C:WindowsSystem32. В данном случае предполагается, что используется кодовая страница западно-европейской версии – 1252. Узнать, какая текущая кодовая страницы, можно с помощью параметра ACP в реестре, аналогично предыдущему способу.
- Переходим по пути C:WindowsSystem32, где следует найти файл c_1252.NLS. По нему нужно кликнуть правой кнопкой мыши, чтобы выбрать меню «Свойства» и открыть вкладку «Безопасность». Там нужно нажать на «Дополнительно».
В разделе «Владелец» кликаем на «Изменить».
Теперь будет открыт раздел «Безопасность» в меню свойства файла. Кликаем по кнопке «Изменить».
Выбираем раздел «Administrators» (Администраторы) и включаем для них полный доступ. Щелкаем на «Ок» и подтверждаем осуществленные изменения разрешений. Кликаем по «Ок» в свойствах файла.
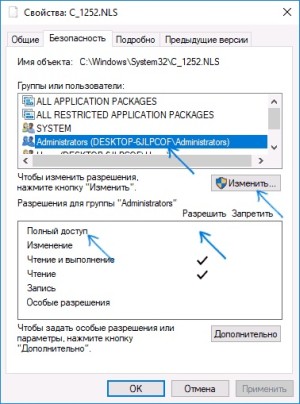
Теперь задача переименовать файл c_1252.NLS. Изменить расширение можно на .bak, чтобы файл не был потерян.
Путем удержания клавиши Ctrl, нужно перетащить файл c_1251.NLS (для кириллицы кодовая страница) располагающийся в C:WindowsSystem32 в иное место данного окна проводника, чтобы была создана копия файла.
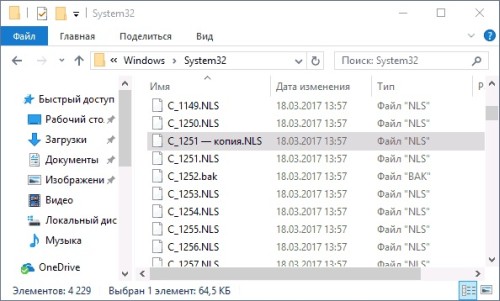
Переименовываем сделанную копию c_1251.NLS в новую c_1252.NLS.
Перезагружаем компьютер.
После выполнения перезагрузки компьютера, в Windows 10 кириллица будет отображаться не как кракозяблы, а в виде русских букв.
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
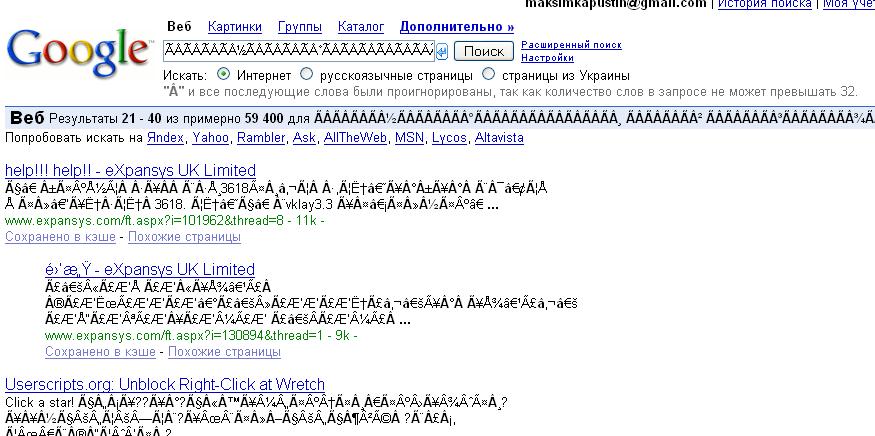
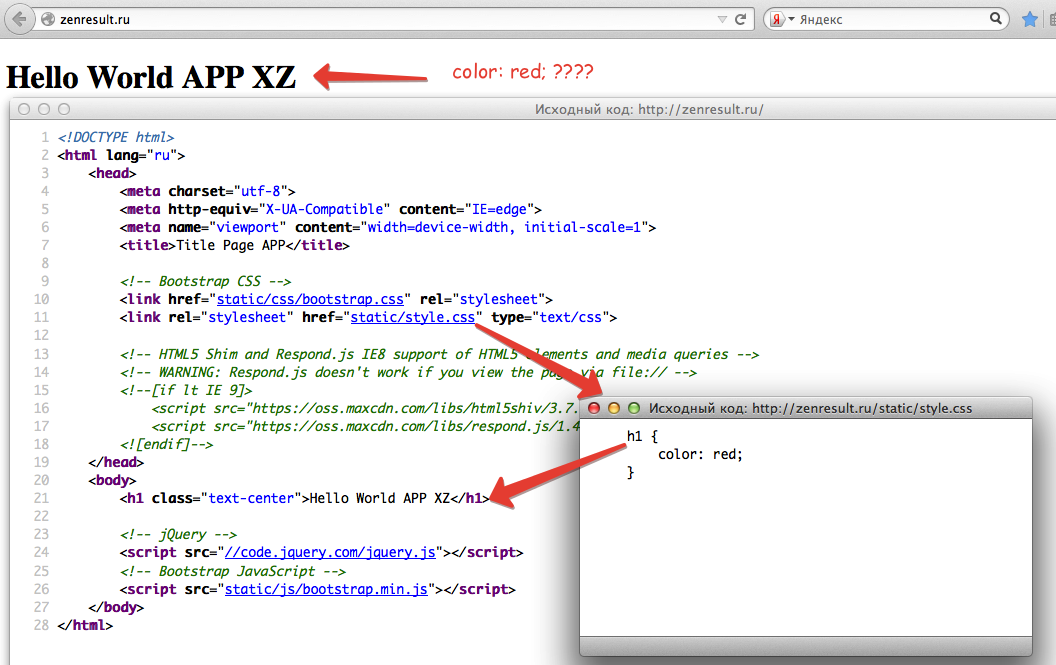
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Неправильная кодировка результатов из базы данных MySQL
Если ваш сайт состоит из статической части (шаблон) и динамической, которая формируется из данных, получаемых из базы данных, то может возникнуть ситуация, когда часть сайта имеет правильную кодировку, а другая часть сайта имеет неправильную. В этом случае бесполезно менять настройки веб-сервера – поскольку всё равно часть страницы будет иметь неправильную кодировку.
Нужно начать с определения кодировки ваших таблиц. Можно посмотреть в phpMyAdmin:
Обратите внимание на столбец «Сравнение», запись «utf8_unicode_ci» означает, что используется кодировка UTF-8. Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin
Для этого:
Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin. Для этого:
mysql -u root -p
Если вы забыли имя базы данных, то выполните команду:
SHOW DATABASES;
Предположим, я хочу посмотреть кодировку для таблиц в базе данных information_schema
USE information_schema;
Если вы забыли имя таблиц, выполните:
SHOW TABLES;
Далее выполните команду, в которой имя_таблицы замените на настоящее имя таблицы:
SHOW FULL COLUMNS FROM имя_таблицы;
Например:
SHOW FULL COLUMNS FROM GLOBAL_STATUS;
Вы увидите примерно следующее:
Смотрите столбец Collation. В моём случае там utf8_general_ci, это, как и utf8_unicode_ci, кодировка UTF-8. Кстати, если вы не знаете в чём разница между кодировками utf8_general_ci, utf8_unicode_ci, utf8mb4_general_ci, utf8mb4_unicode_ci, а также какую кодировку выбрать для базы данных MySQL, то посмотрите эту статью.
Теперь, когда мы узнали кодировку (в моём случае это UTF-8), то при каждом подключении к СУБД MySQL нужно выполнять последовательно запросы:
SET NAMES UTF8 SET CHARACTER SET UTF8 SET character_set_client = UTF8 SET character_set_connection = UTF8 SET character_set_results = UTF8
В PHP это можно сделать примерно так:
$this->mysqli = new mysqli($server, $username, $password, $basename);
if ($this->mysqli->connect_error) {
$this->errorHandler_c->logError(1, 'Connect Error (' . $this->mysqli->connect_errno . ') ' . $this->mysqli->connect_error, $_SERVER );
}
$this->mysqli->query("SET NAMES UTF8");
$this->mysqli->query("SET CHARACTER SET UTF8");
$this->mysqli->query("SET character_set_client = UTF8");
$this->mysqli->query("SET character_set_connection = UTF8");
$this->mysqli->query("SET character_set_results = UTF8");
Обратите внимание, что UTF8 вам нужно заменить на ту кодировку, которая используется для ваших таблиц
Настройте работу с текстом в командной строке
На вкладке «Параметры» разделы «Изменить параметры» и «Выбор текста» помогут выбрать способ взаимодействия с окном командной строки. Когда опция Быстрое редактирование включена, она позволяет выбирать и копировать текст из окна командной строки. Сначала выберите текстовую область, которую хотите скопировать, с помощью мыши или пальца, затем щелкните правой кнопкой мыши, нажмите и удерживайте нажатой клавишу или нажмите Enter. Текст копируется в буфер обмена.
Второй параметр — «Режим вставки» — выполняет ту же функцию, что и клавиша «Вставить клавиатуру»: курсор вставляет символ в его текущую позицию, заставляя все символы, проходящие за ним, на одну позицию дальше. Если режим вставки отключен, то ваш текст перезаписывает любой текст, который уже там.
В Windows 10 введены сочетания клавиш в командной строке, и для их использования необходимо установить флажки рядом с параметром «Включить сочетания клавиш Ctrl» (в разделе «Параметры редактирования») и «Расширенные клавиши выбора текста». опция (в текстовом выделении).
Если вы включите опцию «Фильтровать содержимое буфера обмена при вставке», всякий раз, когда вы вставляете содержимое из буфера обмена в командной строке, специальные символы, такие как вкладки, автоматически удаляются, а умные кавычки преобразуются в обычные.
Первый параметр в выделении текста — «Включить выделение переноса строк», и, когда он активирован, он улучшает способ, которым ваша командная строка обрабатывает выделение текста. Предыдущие версии командной строки позволяли копировать текст из нее только в блочном режиме.
Это означает, что каждый раз, когда вы вставляли содержимое из командной строки в текстовый редактор, вам приходилось вручную исправлять вкладки, перенос слов и т.д. Если вы включите эту опцию, Windows 10 позаботится обо всем этом, поэтому вам больше не придется корректировать поток текста.
Имейте в виду, что если вы установите флажок рядом с опцией «Использовать устаревшую консоль (требует перезапуска, влияет на все консоли)» внизу, вы вернетесь к предыдущей версии консоли, что означает, что многие из перечисленных выше параметров являются серыми. и что вкладка терминала полностью исчезла.
Если вы перейдете на вкладку «Терминал», есть еще один параметр, который влияет на использование командной строки в разделе «Прокрутка терминала» внизу. Установите флажок рядом с параметром «Отключить прокрутку вперед», и теперь вы больше не можете прокручивать страницу ниже последней введенной команды.
Когда вы закончите изменять настройки, все, что вам нужно сделать, это нажать или нажать OK, чтобы применить их. Если ваши изменения не применяются немедленно, перезапуск командной строки должен позаботиться об этом.
Настройте цвета, используемые в командной строке
Цветовая схема по умолчанию, вызывающая зевок в командной строке, конфликтует с яркими цветами, встречающимися в большинстве приложений Windows 10. К счастью, мы можем развлекаться, изменяя его внешний вид с помощью параметров на вкладке «Цвета», которая полностью настраивает цвета, используемые в командной строке.
Первое, что вы видите в верхнем левом углу вкладки, это четыре элемента, которые вы можете настроить: текст на экране, фон экрана, всплывающий текст и фон всплывающего окна. Хотя Screen Text меняет цвет текста, отображаемого в окне командной строки, а Screen Screen меняет фон для этого текста, последние два параметра не представляют особого интереса, так как всплывающие окна чаще всего встречаются разработчиками.
Чтобы изменить цвет для любого из этих активов, сначала выберите его из списка. Затем вы можете щелкнуть или нажать один из предустановленных цветов, показанных ниже, или использовать раздел «Выбранные значения цвета», чтобы выбрать собственный цвет, вставив его десятичный код цвета RGB.
Если заданный фон для окна командной строки имеет тот же цвет, что и текст, это может сбить пользователей с толку, делая невозможным чтение любого отображаемого текста. К счастью, поля «Выбранные цвета экрана» и «Выбранные всплывающие цвета» обеспечивают обратную связь в реальном времени и позволяют легко выбирать подходящие цвета.


На вкладке «Терминал» вы можете найти дополнительные параметры цвета, представленные в качестве экспериментальных настроек. Вверху раздела «Цвета курсора», который мы уже рассмотрели в предыдущем разделе этого урока, есть раздел «Цвета терминала». Если этот флажок установлен, параметр «Использовать отдельный передний план» позволяет изменять цвет текста, а параметр «Использовать отдельный фон» позволяет настраивать фон.
Используйте значения RGB для определения любых цветов в спектре, соблюдая флажки под каждой опцией, чтобы получить предварительный просмотр ваших вариантов цвета в реальном времени. Если включены цвета терминала (т.е. их флажки установлены), цвета, заданные для текста и фона на вкладке «Терминал», имеют приоритет над цветами, выбранными на вкладке «Цвета», и переопределяют их.
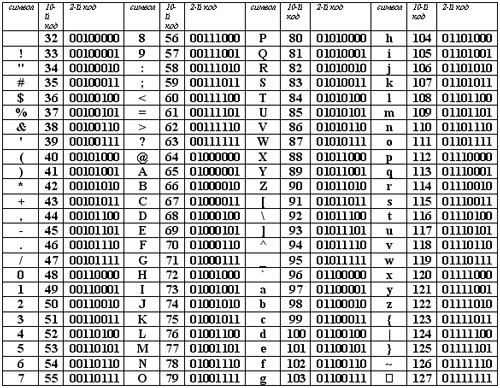
Таблица кодов символов Windows-1251
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Данная кодировка пользуется довольно большой популярностью в восточно-европейских странах.
Windows-1251 выгодно отличается от других 8-битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в традиционной русской типографике для обычного текста (отсутствует только знак ударения). Кириллические символы идут в алфавитном порядке.
Windows-1251 также содержит все символы для близких к русскому языку языков: белорусского, украинского, сербского, македонского и болгарского.
На практике этого оказалось достаточно, чтобы кодировка Windows-1251 закрепилась в интернете вплоть до распространения UTF-8.
| 000 | 00 | NOP | 128 | 80 | Ђ |
| 001 | 01 | SOH | 129 | 81 | Ѓ |
| 002 | 02 | STX | 130 | 82 | ‚ |
| 003 | 03 | ETX | 131 | 83 | ѓ |
| 004 | 04 | EOT | 132 | 84 | „ |
| 005 | 05 | ENQ | 133 | 85 | … |
| 006 | 06 | ACK | 134 | 86 | † |
| 007 | 07 | BEL | 135 | 87 | ‡ |
| 008 | 08 | BS | 136 | 88 | € |
| 009 | 09 | TAB | 137 | 89 | ‰ |
| 010 | 0A | LF | 138 | 8A | Љ |
| 011 | 0B | VT | 139 | 8B | ‹ |
| 012 | 0C | FF | 140 | 8C | Њ |
| 013 | 0D | CR | 141 | 8D | Ќ |
| 014 | 0E | SO | 142 | 8E | Ћ |
| 015 | 0F | SI | 143 | 8F | Џ |
| 016 | 10 | DLE | 144 | 90 | ђ |
| 017 | 11 | DC1 | 145 | 91 | ‘ |
| 018 | 12 | DC2 | 146 | 92 | ’ |
| 019 | 13 | DC3 | 147 | 93 | “ |
| 020 | 14 | DC4 | 148 | 94 | ” |
| 021 | 15 | NAK | 149 | 95 | • |
| 022 | 16 | SYN | 150 | 96 | – |
| 023 | 17 | ETB | 151 | 97 | — |
| 024 | 18 | CAN | 152 | 98 | |
| 025 | 19 | EM | 153 | 99 | |
| 026 | 1A | SUB | 154 | 9A | љ |
| 027 | 1B | ESC | 155 | 9B | › |
| 028 | 1C | FS | 156 | 9C | њ |
| 029 | 1D | GS | 157 | 9D | ќ |
| 030 | 1E | RS | 158 | 9E | ћ |
| 031 | 1F | US | 159 | 9F | џ |
| 032 | 20 | SP | 160 | A0 | |
| 033 | 21 | ! | 161 | A1 | Ў |
| 034 | 22 | “ | 162 | A2 | ў |
| 035 | 23 | # | 163 | A3 | Ћ |
| 036 | 24 | $ | 164 | A4 | ¤ |
| 037 | 25 | % | 165 | A5 | Ґ |
| 038 | 26 | & | 166 | A6 | ¦ |
| 039 | 27 | ‘ | 167 | A7 | § |
| 040 | 28 | ( | 168 | A8 | Ё |
| 041 | 29 | ) | 169 | A9 | |
| 042 | 2A | * | 170 | AA | Є |
| 043 | 2B | + | 171 | AB | |
| 044 | 2C | , | 172 | AC | ¬ |
| 045 | 2D | – | 173 | AD | |
| 046 | 2E | . | 174 | AE | |
| 047 | 2F | 175 | AF | Ї | |
| 048 | 30 | 176 | B0 | ° | |
| 049 | 31 | 1 | 177 | B1 | ± |
| 050 | 32 | 2 | 178 | B2 | І |
| 051 | 33 | 3 | 179 | B3 | і |
| 052 | 34 | 4 | 180 | B4 | ґ |
| 053 | 35 | 5 | 181 | B5 | µ |
| 054 | 36 | 6 | 182 | B6 | ¶ |
| 055 | 37 | 7 | 183 | B7 | · |
| 056 | 38 | 8 | 184 | B8 | ё |
| 057 | 39 | 9 | 185 | B9 | № |
| 058 | 3A | 186 | BA | є | |
| 059 | 3B | ; | 187 | BB | |
| 060 | 3C | 190 | BE | ѕ | |
| 063 | 3F | ? | 191 | BF | ї |
| 064 | 40 | @ | 192 | C0 | А |
| 065 | 41 | A | 193 | C1 | Б |
| 066 | 42 | B | 194 | C2 | В |
| 067 | 43 | C | 195 | C3 | Г |
| 068 | 44 | D | 196 | C4 | Д |
| 069 | 45 | E | 197 | C5 | Е |
| 070 | 46 | F | 198 | C6 | Ж |
| 071 | 47 | G | 199 | C7 | З |
| 072 | 48 | H | 200 | C8 | И |
| 073 | 49 | I | 201 | C9 | Й |
| 074 | 4A | J | 202 | CA | К |
| 075 | 4B | K | 203 | CB | Л |
| 076 | 4C | L | 204 | CC | М |
| 077 | 4D | M | 205 | CD | Н |
| 078 | 4E | N | 206 | CE | О |
| 079 | 4F | O | 207 | CF | П |
| 080 | 50 | P | 208 | D0 | Р |
| 081 | 51 | Q | 209 | D1 | С |
| 082 | 52 | R | 210 | D2 | Т |
| 083 | 53 | S | 211 | D3 | У |
| 084 | 54 | T | 212 | D4 | Ф |
| 085 | 55 | U | 213 | D5 | Х |
| 086 | 56 | V | 214 | D6 | Ц |
| 087 | 57 | W | 215 | D7 | Ч |
| 088 | 58 | X | 216 | D8 | Ш |
| 089 | 59 | Y | 217 | D9 | Щ |
| 090 | 5A | Z | 218 | DA | Ъ |
| 091 | 5B | 219 | DB | Ы | |
| 092 | 5C | 220 | DC | Ь | |
| 093 | 5D | 221 | DD | Э | |
| 094 | 5E | ^ | 222 | DE | Ю |
| 095 | 5F | _ | 223 | DF | Я |
| 096 | 60 | ` | 224 | E0 | а |
| 097 | 61 | a | 225 | E1 | б |
| 098 | 62 | b | 226 | E2 | в |
| 099 | 63 | c | 227 | E3 | г |
| 100 | 64 | d | 228 | E4 | д |
| 101 | 65 | e | 229 | E5 | е |
| 102 | 66 | f | 230 | E6 | ж |
| 103 | 67 | g | 231 | E7 | з |
| 104 | 68 | h | 232 | E8 | и |
| 105 | 69 | i | 233 | E9 | й |
| 106 | 6A | j | 234 | EA | к |
| 107 | 6B | k | 235 | EB | л |
| 108 | 6C | l | 236 | EC | м |
| 109 | 6D | m | 237 | ED | н |
| 110 | 6E | n | 238 | EE | о |
| 111 | 6F | o | 239 | EF | п |
| 112 | 70 | p | 240 | F0 | р |
| 113 | 71 | q | 241 | F1 | с |
| 114 | 72 | r | 242 | F2 | т |
| 115 | 73 | s | 243 | F3 | у |
| 116 | 74 | t | 244 | F4 | ф |
| 117 | 75 | u | 245 | F5 | х |
| 118 | 76 | v | 246 | F6 | ц |
| 119 | 77 | w | 247 | F7 | ч |
| 120 | 78 | x | 248 | F8 | ш |
| 121 | 79 | y | 249 | F9 | щ |
| 122 | 7A | z | 250 | FA | ъ |
| 123 | 7B | { | 251 | FB | ы |
| 124 | 7C | | | 252 | FC | ь |
| 125 | 7D | } | 253 | FD | э |
| 126 | 7E | ~ | 254 | FE | ю |
| 127 | 7F | DEL | 255 | FF | я |
Описание специальных (управляющих) символов
Первоначально управляющие символы таблицы ASCII (диапазон 00-31, плюс 127) были разработаны для того, чтобы управлять устройствами аппаратных средств, таких как телетайп, ввод данных на перфоленту и др.Управляющие символы (кроме горизонтальной табуляции, перевода строки и возврата каретки) не используются в HTML-документах.
КодОписание
NUL, 00
Null, пустой
SOH, 01
Start Of Heading, начало заголовка
STX, 02
Start of TeXt, начало текста
ETX, 03
End of TeXt, конец текста
EOT, 04
End of Transmission, конец передачи
ENQ, 05
Enquire. Прошу подтверждения
ACK, 06
Acknowledgement. Подтверждаю
BEL, 07
Bell, звонок
BS, 08
Backspace, возврат на один символ назад
TAB, 09
Tab, горизонтальная табуляция
LF, 0A
Line Feed, перевод строкиСейчас в большинстве языков программирования обозначается как
VT, 0B
Vertical Tab, вертикальная табуляция
FF, 0C
Form Feed, прогон страницы, новая страница
CR, 0D
Carriage Return, возврат кареткиСейчас в большинстве языков программирования обозначается как
SO, 0E
Shift Out, изменить цвет красящей ленты в печатающем устройстве
SI, 0F
Shift In, вернуть цвет красящей ленты в печатающем устройстве обратно
DLE, 10
Data Link Escape, переключение канала на передачу данных
DC1, 11 DC2, 12DC3, 13DC4, 14
Device Control, символы управления устройствами
NAK, 15
Negative Acknowledgment, не подтверждаю
SYN, 16
Synchronization. Символ синхронизации
ETB, 17
End of Text Block, конец текстового блока
CAN, 18
Cancel, отмена переданного ранее
EM, 19
End of Medium, конец носителя данных
SUB, 1A
Substitute, подставить. Ставится на месте символа, значение которого было потеряно или испорчено при передаче
ESC, 1B
Escape Управляющая последовательность
FS, 1C
File Separator, разделитель файлов
GS, 1D
Group Separator, разделитель групп
RS, 1E
Record Separator, разделитель записей
US, 1F
Unit Separator, разделитель юнитов
DEL, 7F
Delete, стереть последний символ.